

Vi releaser cirka hver 14. dag. Men vi har deployet mere end 2.000 gange i år.
Forvirret?
Vi har adskilt det "at deploye" fra det "at release".
Jeg har tre tips til at komme i gang med Continuous Delivery længere nede. Men først lidt om, hvorfor det handler om mennesker, før det handler om teknologi.
Continuous Delivery er mere end teknologi
Vores kunders har ingen tekniske forventninger til en release. Men på tech-konferencerne bliver vi kun fortalt om de tekniske forudsætninger for Continuous Delivery.
Det vigtigste for vores kunder er imidlertid noget helt andet:
- Skal brugerne ændrer deres arbejdsgange efter releasen?
- Skal vores it-afdeling ændrer deres arbejdsgange i forbindelse med releasen?
- Kan brugerne arbejde på en smartere måde efter releasen?
- Kan brugerne spare tid efter releasen?
Derfor indeholder en release mere end et deploy. Den kan fx indeholde:
- Foreløbige release notes
- Endelige release notes
- Webinarer
- Opdateret datamodel
- Opdaterede brugervejledninger
- Opdaterede tekniske vejledninger
- Osv.
Alt det er nødvendigt for, at vores brugere kan få deres hverdag til at fungere.
Og alt det kan man naturligvis ikke opdatere ved hvert deploy. I hvert fald ikke hvis man deployer 2.000 gange om året. Og selvom man kunne, ville kunderne sikkert ikke kunne fordøje det.
Vi har adskilt release fra deploy, så brugerne kan fordøje ny funktionalitet i det tempo, de har brug for, samtidig med, at vi kan deploye ændringer i det tempo, vi har brug for.
Vi undgår bug-arkæologi. Brugerne får løst fejl hurtigere.
Der er jo ingen mennesker, der kan huske det kode, de skrev for flere måneder siden. Det kalder vi bug-arkæologi. Og det stinker. Både for de brugere, der skal leve med fejlen, og for de udviklere, supportere og driftsfolk, der skal lede efter den.
Men får du som udvikler en fejl ind på noget, du lavede i forgårs, så ved du ofte, hvad fejlen er øjeblikkeligt. For du har jo lige introduceret den. Den er billig at rette, og vi kan få den hurtig ud til brugerne.
Det er en virkelig dejlig måde at arbejde på.
Fordelen er, at vi altid ved, præcis hvad vi deployer, fordi ændringerne er så små. Hvis vi hele tiden får små kodeændringer ud, så ved vi lige præcis, hvad der gik galt, hvis der opstår en fejl. Og vi får hele tiden sikkerhed for, at det vi bygger, også fungerer i praksis. Hvis ikke, så retter vi det jo bare til i morgen.
Vi kan også teste prototyper af hos udvalgte kunder, så de kan give feedback ikke bare på prototypen, men på prototypen baseret på deres egne data i produktion. Derfor kan vi ramme meget mere præcist, når vi frigiver den endelige funktionalitet.
Små ændringer giver konstant feedback
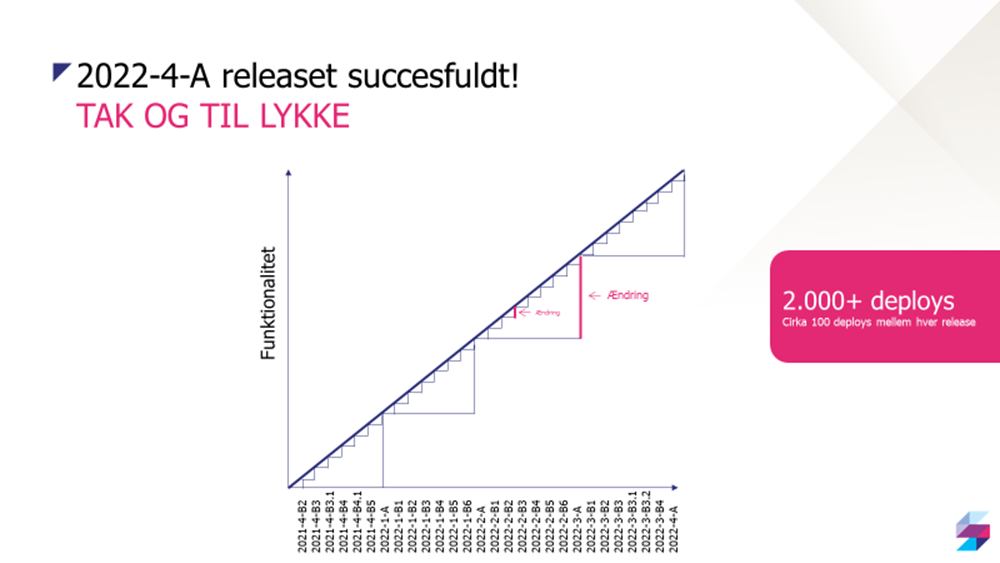
Alle de "små trapper" i figuren her er vores releases. Der er mange. Derfor er de små. Og de små ændringer er nemme at holde styr på.
Og selvom der er mange releases, er der langt flere deploys.
Imellem hver af de "små trapper" i figuren - altså imellem hver release - er der cirka 100 deploys. Altså 100 "baby-trapper", der ikke er tegnet ind i figuren, men hvor vi er i granuleret kontrol over præcis, hvad vi ændrer på miljøet. Det betyder, at selve releasen nogle gange kan bestå i blot at ændre en feature-toggle, som får den nye funktionalitet til at komme til syne for brugerne i brugergrænsefladen.
De store trapper i figuren - hvad er det? Det er vores gamle release-cyklus. Den, vi brugte, før vi gik over til continuous delivery. I dag er det næsten utænkeligt for os at deploye så meget funktionalitet - så mange ændringer - på en gang.
Sådan kommer du i gang
Jeg har et yndlingseksempel på vores rejse mod continuous delivery.
Det første team til at starte med at release hvert 14. dag var nemlig ikke det team, der brugte den nyeste teknologi, hvor alting var teknisk muligt. Nej, det var helt omvendt det team, der sad på den ældste teknologi!
Hvor det var sværest at deploye.
Hvor der var dårligst test-automatisering.
Hvor der var størst behov for manuel test.
Hvor koden var sværest at forstå.
Hvor risikoen for at introducere fejl var størst.
Hvordan i al verden kunne de lykkes med at deploye hver 14. dag på et stykke legacy-software? Og før alle de andre teams, som sad på meget mere moderne teknologi. Svaret er hårdt arbejde, vilje og lidt mod. Og så skal man i øvrigt ikke glemme: At release handler som sagt om andet end teknologi, og hvis din platform er moden, så er dine releaseprocesser sikkert også modne. Det var i hvert fald vores tilfælde Derfor bliver du måske overrasket over, at det trods alt ikke er sværere at release ofte - for du har faktisk ret godt styr på dine deploys og på din releaseproces på et stykke modent software. Moden betyder ikke bare legacy. Det betyder faktisk også ... moden.
For en release er ikke bare et teknisk deploy. Og alle de besværgelser rundt om et deploy, som gør det til en release, er du garanteret 100-metermester i på dine gamle applikationer.
På dine nye applikationer - på al den nye teknologi - er det tekniske deploy muligvis nemmere, men alt det andet mangler.
Derfor kunne det team, der sad på den ældste software, være de første til at release hver 14. dag. Men der stoppede glæden til gengæld også. De kommer aldrig til at deploye 10-20 gange hver dag. Dertil er de tekniske barrierer simpelthen for høje, uanset hvor meget mod, vilje og hårdt arbejde, de ligger i det :-)
Da vi først havde erkendt, hvad det betød at adskille deploys fra releases, udarbejdede vi en leverancestrategi. Ikke en contiuous deploy-strategi. Men en strategi for den samlede leverance. Vi satte os et mål, og så gik vi i gang.
Det var vores vurdering, at hvis vi forretningsmæssigt skulle lykkes med nogle høje ambitioner, så skulle vi lykkes med en continuous delivery-strategi. Det var med andre ord ikke "bare" noget, udviklingsafdelingen lavede, når vi lige havde tid. Vi havde en klar ambition med det, som var rodfæstet i forretningen.
Leverancestrategien var baseret på en vision, og vi accepterede, at det ville være en ændring, der tog tid. Og med tid mener jeg - i vores tilfælde - flere år, før det kørte, som det skulle. Men en klar vision giver mulighed for stille og roligt at få alting til at pege i den samme retning.
Vores første udkast til en vision blev formuleret tilbage i 2018, og det så ud som nedenfor. I dag er det ret præcist det, vi er lykkedes med, og som vi har opereret efter i efterhånden et par år.

Én ting er, at vi skulle lykkes med teknisk at kunne deploye.
En anden ting er, at vi skulle lykkes med at levere den nødvendige systemdokumentation, webinarer osv. ud til kunderne.
Men en helt tredje ting var, at udviklerne skulle være villige til at følge strategien.
Der var de udviklere, der synes, at det var superfedt. Men også dem, der var lidt små-ligeglade. Og måske ovenikøbet dem, der slet ikke synes, at det var nødvendigt. Og alle skulle med.
Arkitekterne på teamet gjorde et stort stykke arbejde for at forklare, hvad det betød for den enkelte udvikler, og hvorfor de troede på konceptet, og udviklerne havde tillid til og var lydhøre over for argumenterne og gav godt med- og modspil. Det, der nok solgte flest billetter hos de fleste udviklere, var forestillingen om at undgå "bug-arkæologi". Alle kunne se en fordel ved at få hurtig feedback på deres ændringer.
Men vi traf også lavpraktiske beslutninger, som der skulle være opbakning til.
Vi besluttede fx, at alle moduler skulle deployes mindst hver 14. dag, uanset om der var ændringer til modulet eller ej.
Hvorfor egentlig det - for kan der være opstået fejl i et modul, som ikke har nogen ændringer?
Måske ikke. Men der kan være opstået fejl i deploy-pipelinen. Et certifikat der er udløbet. En infrastrukturkomponent, der har ændret sig. Eller hvad ved jeg.
Derfor synes vi, at det var den rigtige beslutning, men det er jo ikke sikkert, at vi har ret. I hvert fald var det en af de knaster, som det tog lidt tid at få alle til at købe ind på. Og uanset om det var den rigtige beslutning eller ej, så endte det med at være en del af vores leverancestrategi, og alle er endt med at følge princippet.
Mennesker over teknologi
Og så er vi tilbage ved udgangspunktet. Vi tror på, at Continuous Delivery gør vores system til et bedre sted at være bruger. Det er noget, som vores driftsfolk og udviklere skal leve og ånde som en kultur hver dag. Og samtidig skal vi kunne leve op til alle de forventninger, vores kunder har, og vores kundesupportere, konsulenter, sælgere osv. skal stå på mål for det.
Derfor har den teknologiske ændring formodentlig været den mindste del af projektet, og ændringen hos en hel masse mennesker har været den største.